
好的,既然已經有這樣的結果,那我們就來把策略把打包成 strategy,並且對策略進行最佳化,來看一下到底哪些 filters 效果比較好。
a. 策略打包
第一章有寫到如何打包策略,這次再來演練一遍。
於程式碼最上方先導入 finlab_crypto 的 strategy,再建造一個裝飾器,然後寫一個函式以便等等把程式碼包住,再把歷史價格丟進函式的參數裡面:
from finlab_crypto import Strategy
@Strategy()
def trend_strategy(ohlcv):
然後在函式下方的程式碼,直到進出場點為止,全部反白按 Tab 鍵,讓策略能夠被函式包住,之後再進出場點下方 return 進出場點。
我們先把可視化的程式碼去掉,程式碼看起來像這樣:
from finlab_crypto import Strategy
@Strategy()
def trend_strategy(ohlcv):
filter_name = 'wma'
close = ohlcv.close
sma20 = indicators.trends[filter_name](close, 20)
sma60 = indicators.trends[filter_name](close, 60)
entries = (sma20 > sma60) & (sma20.shift() < sma60.shift())
exits = (sma20 < sma60) & (sma20.shift() > sma60.shift())
return entries, exits
現在創建回測圖表,於最下方寫上:
trend_strategy.backtest(ohlcv, freq = '4h', plot = True)
注意上述程式碼別被函式包住。
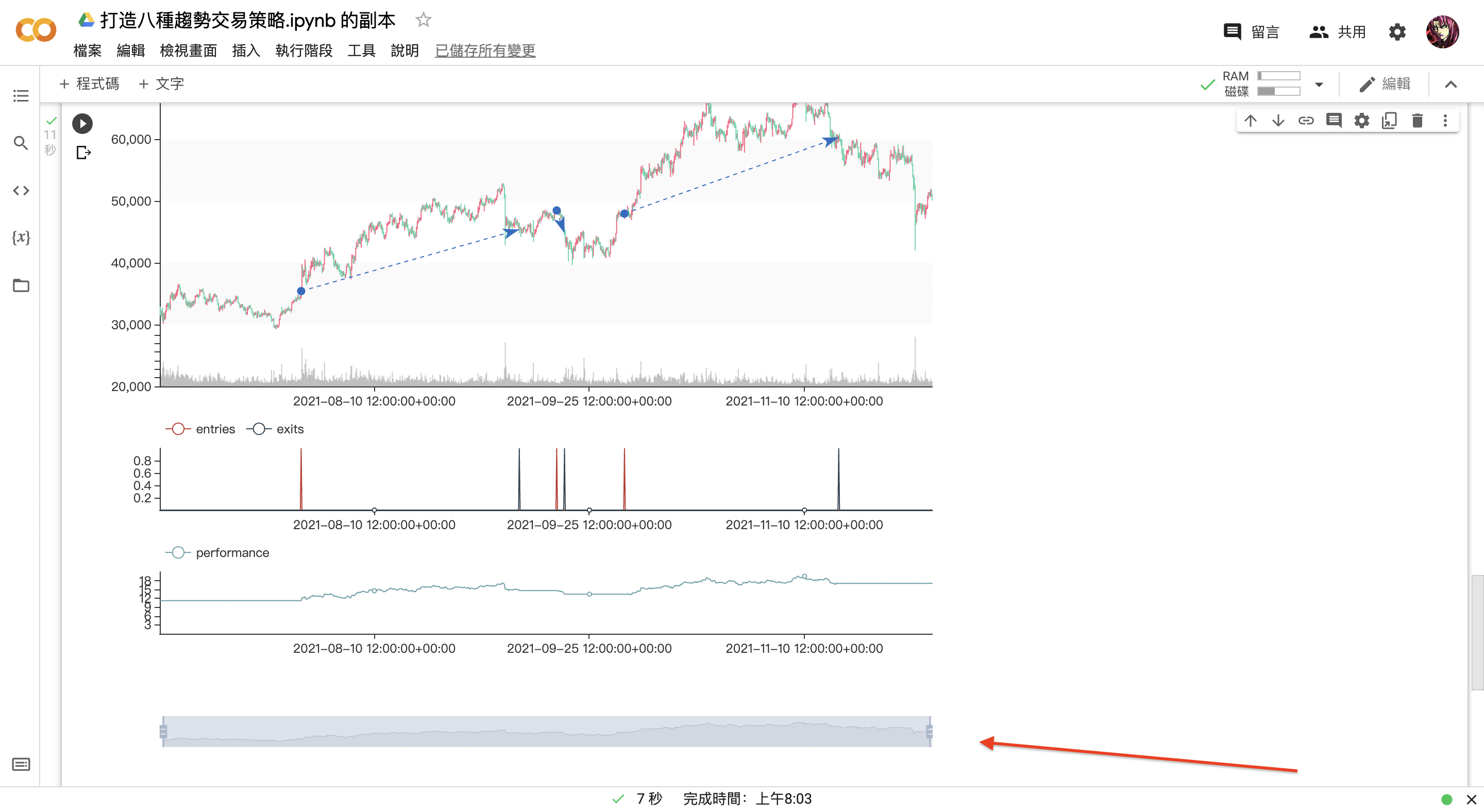
於圖上箭頭指向的時間軸全部拉長,會發現賺了不少。
b. 策略最佳化
但這就是最好了嗎?還不是,應該還有優化的可能,所以我們現在要對這個策略進行最佳化。
首先讓我們確定一下,哪些參數是可以被改變的?
顯然是 filters 和進出場點的位置,換句話說就是 'wma'、20、60。
於是我們將這參數的所有可能性進行枚舉,看哪一種搭配最好,這就是最佳化。
於裝飾器內部寫上上述三個參數:
@Strategy(filter_name = 'sma', n1 = 20, n2 = 60)
然後再把三個參數也寫到函式裡面去取代原本的參數,讓每當裝飾器內的參數改變時,裡面的計算也跟著改變:
from finlab_crypto import Strategy
@Strategy(filter_name = 'sma', n1 = 20, n2 = 60)
def trend_strategy(ohlcv):
filter_name = trend_strategy.filter_name
n1 = trend_strategy.n1
n2 = trend_strategy.n2
close = ohlcv.close
sma20 = indicators.trends[filter_name](close, n1)
sma60 = indicators.trends[filter_name](close, n2)
entries = (sma20 > sma60) & (sma20.shift() < sma60.shift())
exits = (sma20 < sma60) & (sma20.shift() > sma60.shift())
return entries, exits
trend_strategy.backtest(ohlcv, freq = '4h', plot = True)
再來要把這三個參數的所有可能性做枚舉。
怎麼做到呢?來一步一步實做看看,從 filter 的所有可能性開始。
先創建一個新的儲存格:寫上:
list(indicators.trends.keys())
上述程式碼能叫出所有 filters 的名稱,並形成一個串列。
我們先返回到上一個儲存格,在 return 下方(別被函式包住)寫上一個字典並取名 variables,於字典內部放入三個參數名稱:
variables = {'filter_name': ,'n1':, 'n2': }
把叫出所有 filters 名稱的程式碼剪下貼上到 'filter_name' 面前:
variables = {'filter_name': list(indicators.trends.keys()),'n1':, 'n2': }
最後於 variables 上方導入 numpy,在 n1 與 n2 面前寫上:np.arange(20, 300, 20)
於最後一行的 ohlcv 旁邊寫上 variables = variables。
程式碼最後長這樣:
from finlab_crypto import Strategy
@Strategy(filter_name = 'sma', n1 = 20, n2 = 60)
def trend_strategy(ohlcv):
filter_name = trend_strategy.filter_name
n1 = trend_strategy.n1
n2 = trend_strategy.n2
close = ohlcv.close
sma20 = indicators.trends[filter_name](close, n1)
sma60 = indicators.trends[filter_name](close, n2)
entries = (sma20 > sma60) & (sma20.shift() < sma60.shift())
exits = (sma20 < sma60) & (sma20.shift() > sma60.shift())
return entries, exits
import numpy as np
variables = {
'filter_name': list(indicators.trends.keys()),
'n1': np.arange(20, 300, 20),
'n2': np.arange(20, 300, 20)
}
trend_strategy.backtest(ohlcv, variables = variables, freq = '4h', plot = True)
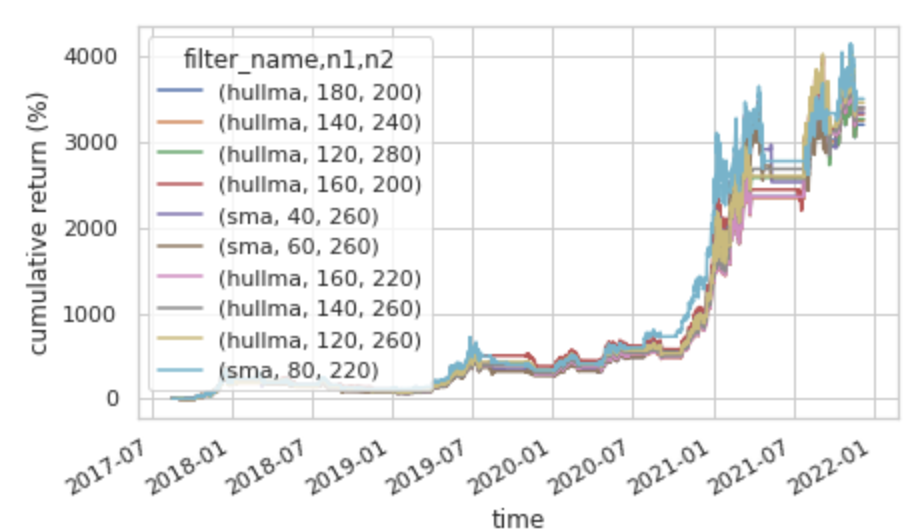
由這一張圖表可以得知,把 filter_name 設為 sma、n1 設為 80、n2 設為 220 能夠得到最高的報酬率。
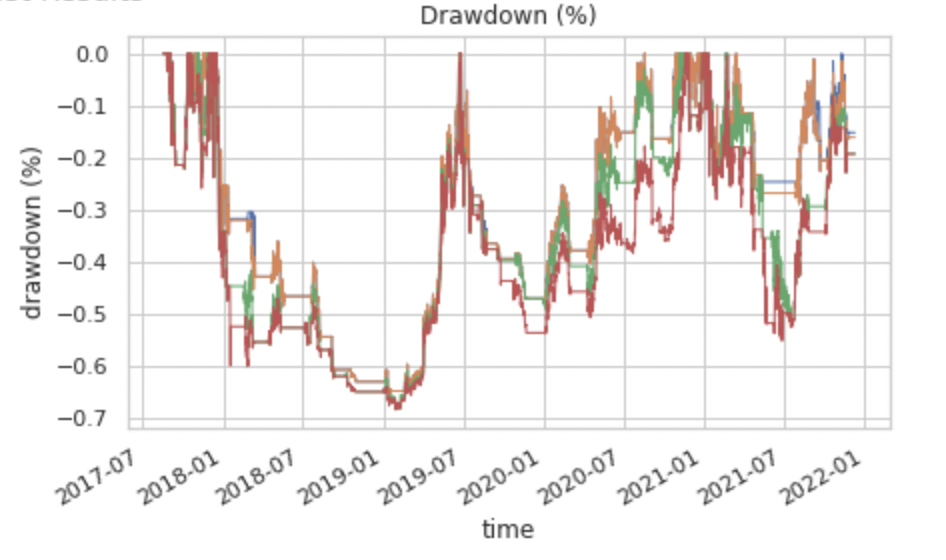
由這一張圖表可以得知,最大的下行風險會來到 70%,意思是當我們拿十萬塊做投資時,最大虧損不會超過七萬塊。
乍看之下好像很嚇人,但如果仔細看,其實只有 2019 年 1 月到 7 月有某個區間來到最大虧損,最常遇到的虧損風險都集中在 10% 到 30% 左右。
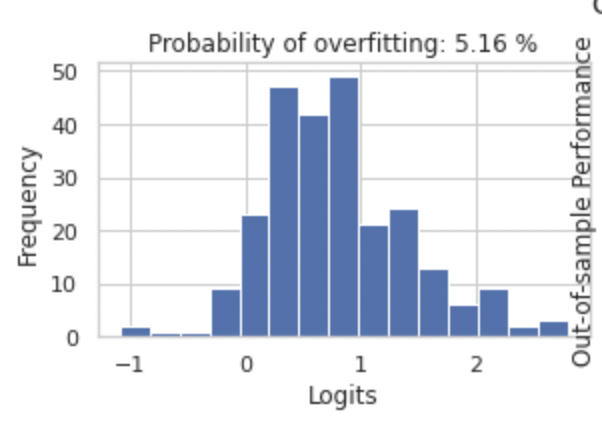
由這一張圖表可以得知,數據幾乎都集中在 0 的右側,加上過擬合風險只有 5.16%,意味著策略非常穩定,幾乎不會有過擬合的風險。
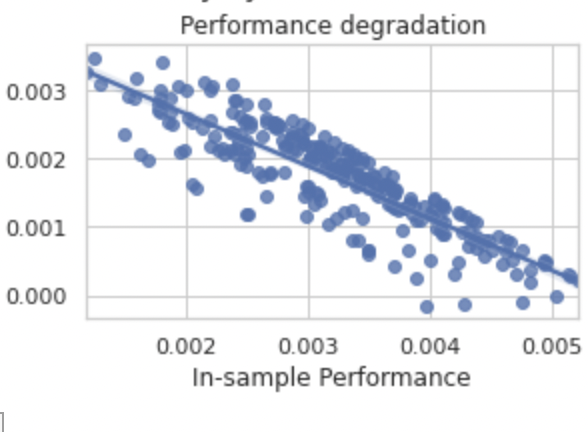
由這一張圖表可以得知,數據幾乎都集中在藍色線段的位置,一樣表示我們的策略很穩定,只是以不同的方式看待。
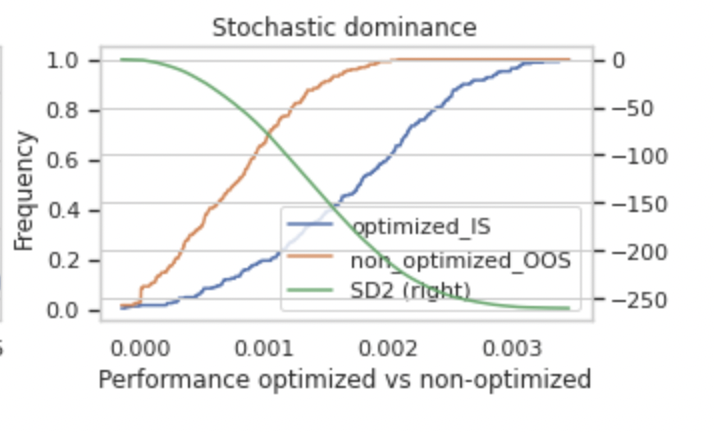
由這一張圖表可以得知,藍色線段在橘色線段的下方,表示我們使用的策略比我們隨機使用一種策略所帶來的報酬率要高出許多。
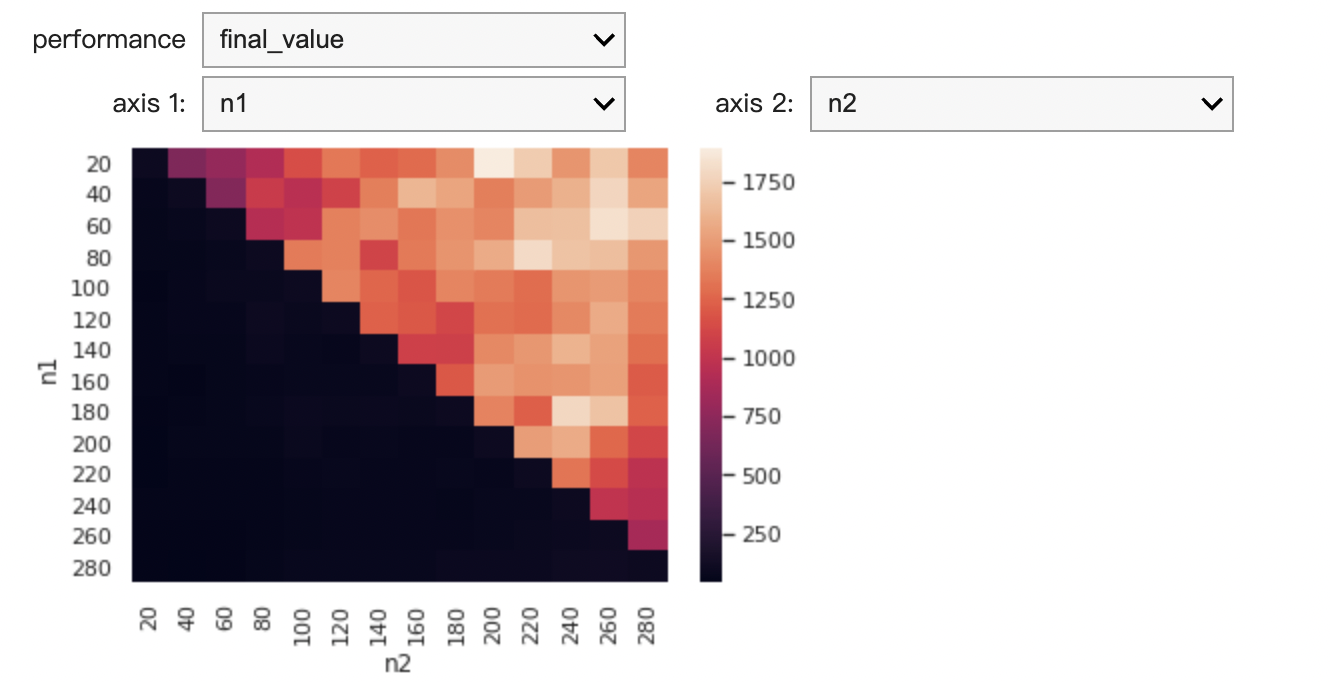
由這張圖表可以得知,把 n1 設為 20、n2 設為 200,會得到較高的報酬率。
由上面的圖表也不難發現,其實不一定需要每張圖表都看,重要的其實是最佳均線參數(第一張)、最高下行風險(第二張)和過擬合機率(第五張),平常製作投資策略時只需要看這三張就夠了。
這一節,我們成功找出最佳的均線和最佳的參數配對。
下一節,我們來試著辨識策略是否有效。


![[第九週] PHP 語法基礎](https://www.coderbridge.com/@peichang6/4aaac6bd83334c698ddf81164ff6f5d0?utm_source=coderbridge-io&utm_medium=blog_related_post_img&utm_campaign=Guolei 的程式設計 Notebook_[第九週] PHP 語法基礎 _@peichang6_https://static.coderbridge.com/images/covers/default-post-cover-2.jpg)


